Software Engineering Complexity
In a previous blog, I talked about how simple approaches, like semantic search + RAG and overloaded context windows with entire codebases, will not suffice for most code evaluation questions. To have confidence in areas like code quality and security, engineering managers require significantly more reliability, depth, and breadth than those basic techniques can answer.
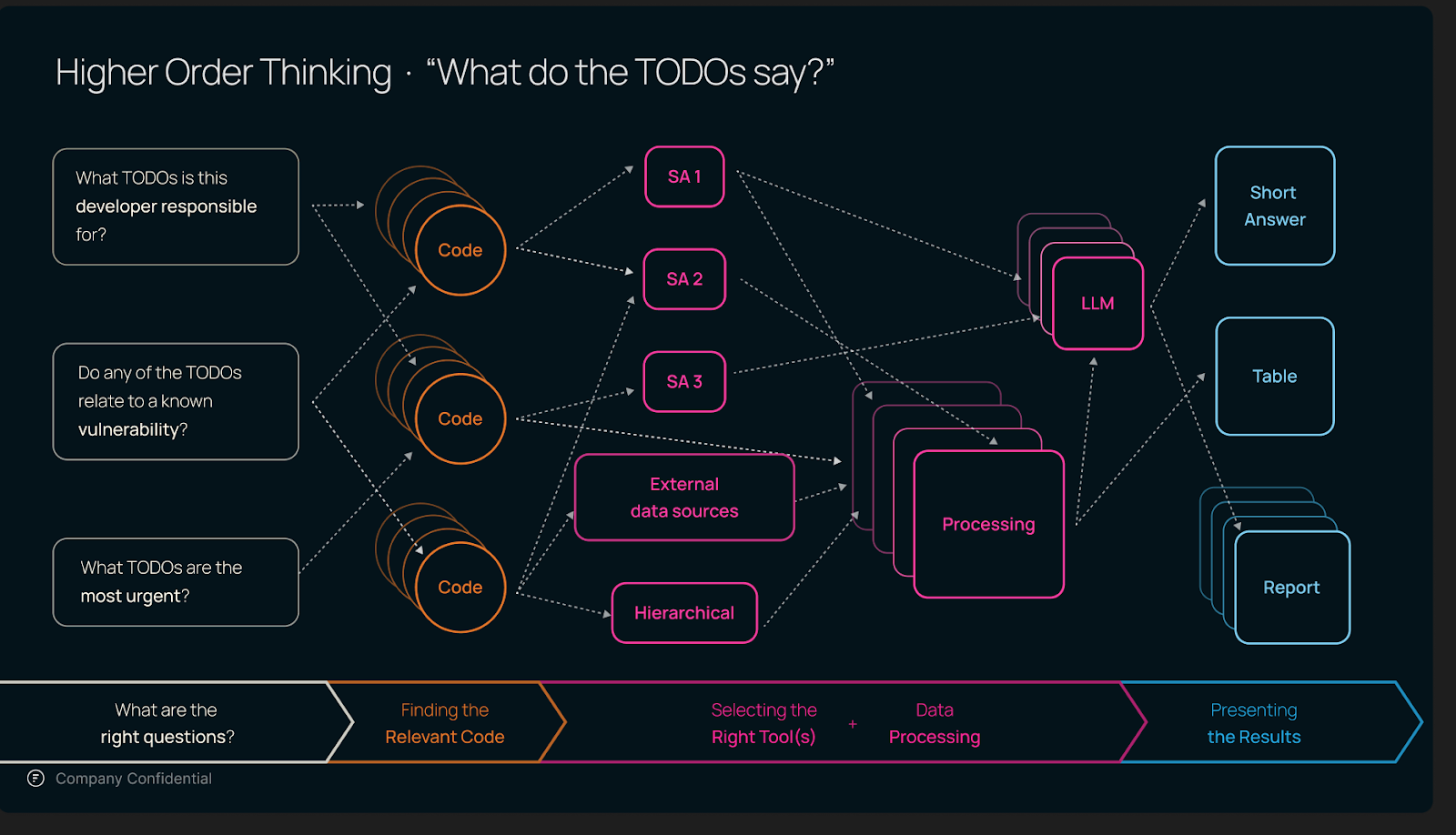
Even questions that seem fairly simple on the surface become more complicated when they are augmented from the superficial question to become valuable to engineering managers. For example, consider the seemingly simple question, “What do the TODOs say?”
Semantic similarity search is trivial and will find code chunks containing the TODOs. If the repo is small enough and the RAG setting on the number of chunks sent to the LLM is large enough, it might even find all of them. If the chunk size is large enough, the chunks will also contain accompanying code to illuminate vague comments, e.g. “refactor this” or “add unit tests.” Of course, if there is too much code in the chunk, the LLM may become confused about where the TODO applies. Thus, in a very simple case where the stars are aligned and one doesn’t care about recall, this naive approach with simple tools will work fine.

In some repos, the parameters behind the search and RAG will be suboptimal, and, therefore, so will the retrieved chunks. Some important information is likely to be omitted from the answer and some confusing noise introduced. When not all of the relevant content fits into one context window—or the default settings for chunking, embedding, similarity search, RAG, etc. don’t work—a more complicated, compound approach is necessary. The LLM will be a member of the ensemble, but it should be combined with other techniques, e.g. static analysis tools, hierarchical construction of the answer from smaller segments, and decomposing questions into smaller, more straightforward parts.
For example, a simple static analysis tool could extract the TODOs with the code they reference (honestly, even grep would be sufficient), with perfect recall. This could be sent to the LLM with the relevant prompt, and the results extracted.

To ensure the context only has highly relevant content, the process of answering evaluation questions should be decomposed into small chunks, e.g. by method, class, file, module, etc. The LLM can be sent these questions hierarchically, starting bottom-up from the leaves, and traversing the code tree. The engineering manager can then get robust, reliable examples. This yields robust, reliable explanations at each level of the code tree, from a high level overview to details that allow deep dive investigations.
Augmenting the code sent to the LLM with the output of a static analysis tool yields an improved answer, a deeper summary, and an audit trail. This allows the engineering manager to get a quick snapshot of the state of the repo, as well as enough information to do a deep investigation.
The described workflow is certainly more complex than Simple RAG, necessitating more complicated software engineering practices. There are multiple tools, prompts, hierarchical summarization techniques, with the orchestration, error handling, data modeling, etc techniques required. It might be tempting to just code an ad hoc solution, rather than building a robust platform. If the TODOs were the only complex question the engineering leader needed answers to, that might indeed be the right path. However, what often seems like a simple application ends up getting drowned in a slew of small incremental add-ons.
The classic example of this phenomenon is when a simple spreadsheet gets augmented with a macro or a couple of formulas. Inevitably, the spreadsheet evolves into a Leviathan, as it gets copied, forked, and altered. Suddenly, there are tons of formulas and macros that nobody trusts, the lineage of the data is questionable, and nobody really understands which is the latest version. That’s if everything goes well. If the intern accidentally deletes something or a macro breaks, all hope is lost.
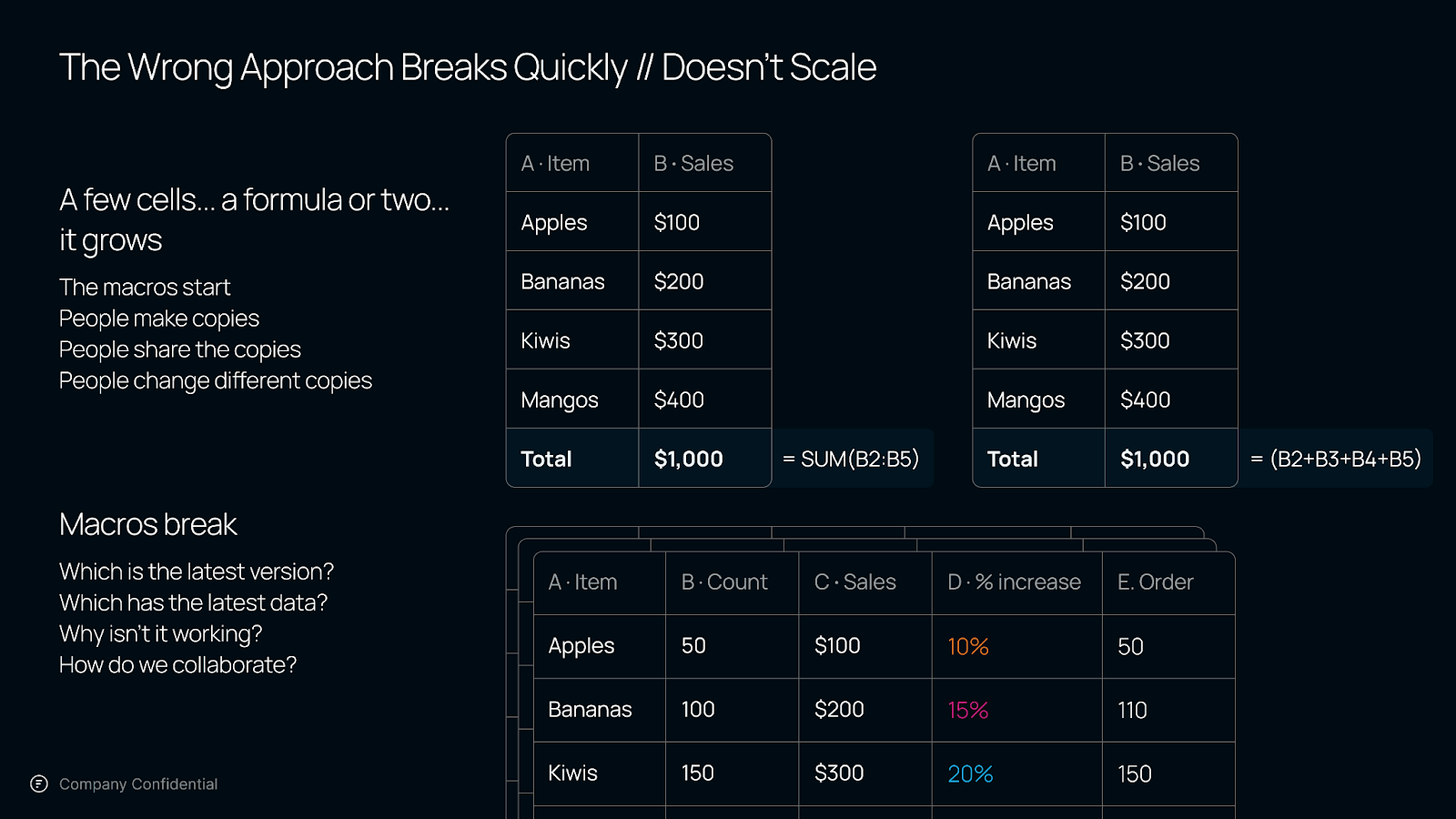
This is exactly where the world of software around LLMs is going. People start with simple solutions like Pinecone and langchain. And they work…for prototypes, simple questions, simple repos, a snapshot of the repo, the individual developer, etc. But very soon, just like in the spreadsheets, the situation becomes more complicated. These fragile solutions become hard to maintain as code and third party dependencies change, as well as corporate policies and regulations. Engineering managers need to know which version of the code the question was asked on. This is in addition to the inherent complexity of the repo evaluation code, e.g. pre- and post-processing scripts wrapping the LLMs’ answers, as well as the shifting underlying LLM changes.
For example, the question on the TODOs is actually more complicated by itself (and still a very simple question). The engineering manager doesn’t want to read one high-level block of text, they want what is actually most important and urgent highlighted and decomposed into areas like security, compliance, and tech debt. Thus, “What do the TODOs say?” isn’t actually the real question–it’s actually multiple questions, centered around which action items are truly the most important action items. These questions are overlapping, but not the same.
Soon, you have this:
At Flux, we have seen the world of compound solutions built around LLMs go in this direction. Even one question becomes more complex when tackled thoroughly. What begins as a simple enhancement to the RAG pipeline becomes a mess of spaghetti workflows, all intertwined. And once the solution becomes untrustworthy, it becomes unusable by the engineering leader. Above all, they need to trust that their analysis tools are accurate and robust across their repos and their evaluation categories. The risks are too high if something is missed, especially for certifications or when evaluating unfamiliar codebases.
At Flux, we’ve lived and understand this, and we’ve built a solution that allows engineering managers to get comprehensive, reliable, deep insights they can trust. In my next blog, I’ll go a little deeper into the Flux architecture and how we orchestrate these tools as part of a robust and comprehensive evaluation platform.

